
中国の研究者らによる「RemoCap: Disentangled Representation Learning for Motion Capture」技術のご紹介。単一映像から人体の動きをキャプチャーする際に遮蔽物があっても比較的高精度な結果を生み出せる新技術!

RemoCap: Disentangled Representation Learning for Motion Capture
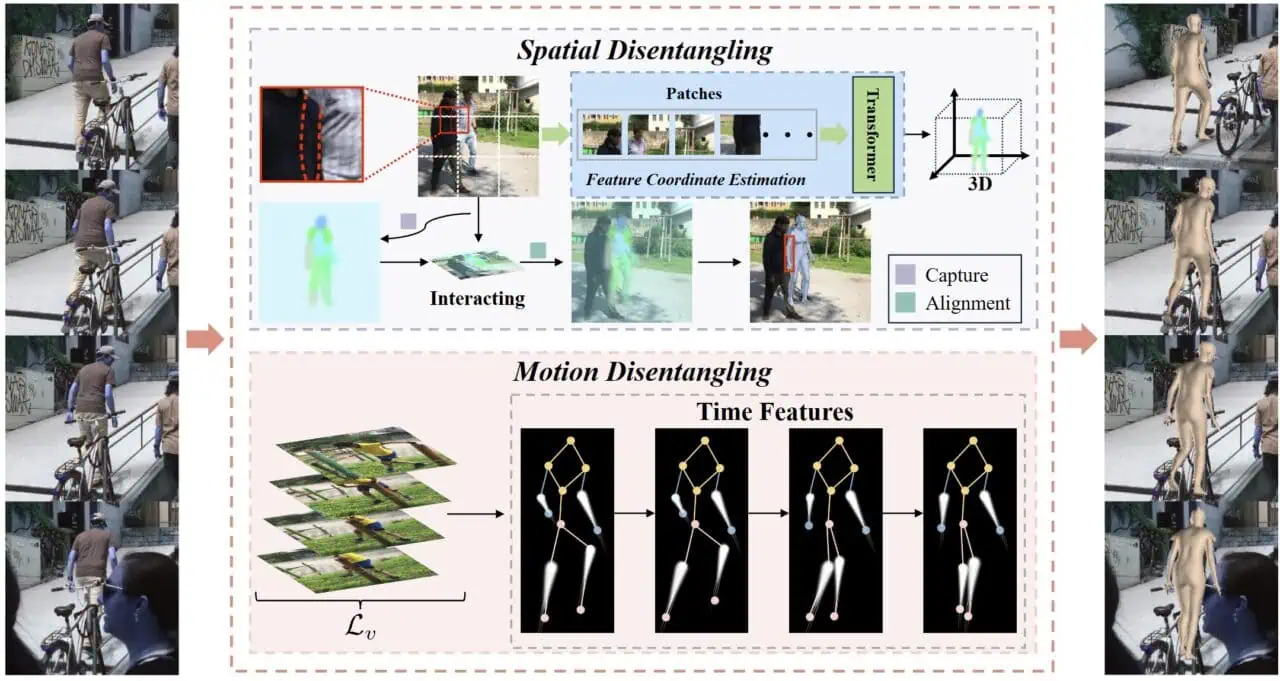
リアルなモーションシーケンスから3D人体を再構成することは、蔓延する複雑なオクルージョンのために、依然として難題である。現在の手法では、オクルージョンのある身体部分のダイナミクスをキャプチャすることが難しく、モデルの貫通や歪んだ動きにつながっています。RemoCapはこれらの限界を克服するために、空間的分離(SD)とモーション分離(MD)を活用します。
SDはターゲットとなる人体と周囲のオブジェクト間のオクルージョン干渉に対処します。これは、次元軸に沿ってターゲットの特徴を分離することで実現します。各次元における空間的位置に基づいて特徴を整列させることで、SDはグローバルウィンドウ内でターゲットオブジェクトの応答を分離し、オクルージョンにもかかわらず正確なキャプチャを可能にする。MDモジュールは、多様なシーンダイナミクスをシミュレートするために、チャンネル単位の時間的シャッフリング戦略を採用する。このプロセスは効果的に動きの特徴を分離し、RemoCapがより忠実にオクルージョン部分を再構成することを可能にします。さらに、本論文では時間的コヒーレンスを促進するシーケンス速度損失を導入する。この損失はフレーム間の速度誤差を抑制し、予測された動きが現実的な一貫性を示すことを保証する。ベンチマークのデータセットで最先端の(SOTA)手法と広範に比較した結果、RemoCapの3D人体再構成における優れた性能が実証された。3DPWデータセットにおいて、RemoCapはMPVPE(81.9)、MPJPE(72.7)、PA-MPJPE(44.1)のメトリクスで最高の結果を達成し、全ての競合を凌駕しています。
この手の研究やサービス展開は中国企業が一足先を進んでいるきがしますねぇ・・
コード自体は少し前に公開されているみたいですので、すでに導入されているサービスも存在していそうですよね。
気になる方は是非チェックしてみてください。
リンク









![Blender完全入門[5.x対応] 形→質感→光→撮影まで全部できる](https://m.media-amazon.com/images/I/51fCuKbCEFL._SL500_.jpg)

![[改訂版]ていねいに学ぶ Blender モデリング入門[Blender 5対応]](https://m.media-amazon.com/images/I/51QA+IHkqpL._SL500_.jpg)









コメント